In this article, we use H.264 as the ultimate compression standard. Although it is no longer the most recent video compression format, it still provides a sufficiently detailed example to explain the close-up concepts of video compression.
Video compression algorithms look for spatial and temporal redundancies. By encoding redundant data a minimum of times, the file size can be reduced. Imagine, for example, a one-minute shot of a character's face slowly changing its expression. It doesn't make sense to encode the background image for every frame:instead, you can encode it once and then refer to it until you know the video changes. This interframe prediction coding is what is responsible for the bewildering artifacts of digital video compression:parts of an old frame moving with incorrect action because something in the coding has gone haywire.
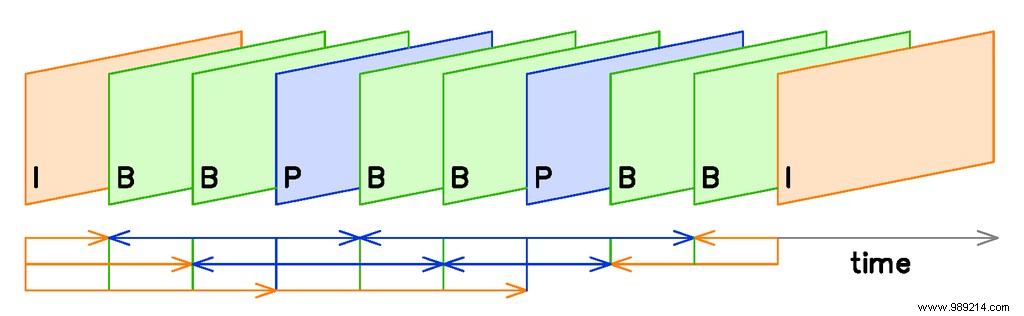
I-frames are compressed independently, in the same way that still images are recorded. Since I-frames do not use any predictive data, the compressed image contains all the data used to display the I-frame. They are always compressed by an image compression algorithm like JPEG. This encoding often takes place in the YCbCr color space, which separates brightness data from color data, allowing motion and color changes to be encoded separately.
For non-predictive codecs like DV and Motion JPEG, that's where we stop. Since there are no predictive images, the only compression that can be achieved is to compress the image into a single frame. It is less efficient but produces a higher quality raw image file.
In codecs that use predictive frames like H.264, I-frames are periodically displayed to "refresh" the data stream by setting a new reference frame. The further apart the I-frames, the smaller the video file can be. However, if the I-frames are too far apart, the accuracy of the video's predictive frames will slowly degrade to unintelligibility. A bandwidth-optimized application would insert I-frames as infrequently as possible without interrupting the video stream. For consumers, the I-frame rate is often indirectly determined by the “quality” setting of the encoding software. Professional-grade video compression software like ffmpeg allows for explicit control.
Video encoders attempt to "predict" the change from frame to frame. The closer their predictions are, the more efficient the compression algorithm. This is what creates the P and B frames. The exact amount, frequency, and order of the predictive frames, as well as the specific algorithm used to encode and reproduce them, are determined by the specific algorithm you are using. .

Consider how H.264 works, as a generalized example. The frame is divided into sections called macroblocks, usually made up of 16 x 16 samples. The algorithm does not encode the raw pixel values for each block. Instead, the encoder looks for a similar block in an older frame, called a reference frame. If a valid reference frame is found, the block will be encoded by a mathematical expression called the motion vector, which describes the exact nature of the change from the reference block to the current block. When the video plays, the video player correctly interprets these motion vectors to "re-transform" the video. If the block does not change at all, no vector is needed.
Once the data is sorted into its frames, it is then encoded into a mathematical expression with the transform encoder. H.264 uses a DCT (Discrete Cosine Transform) to change visual data into a mathematical expression (specifically, the sum of cosine functions oscillating at various frequencies.) The chosen compression algorithm determines the transform encoder. Then the data is “rounded” by the quantifier. Finally, the bits are run through a lossless compression algorithm to reduce the file size once again. It doesn't change the data:it just organizes it into the most compact form possible. Then the video is compressed, smaller than before, and ready to watch.
Image credit:VC Demo, itu delft